We introduce
![]() R2I-Bench
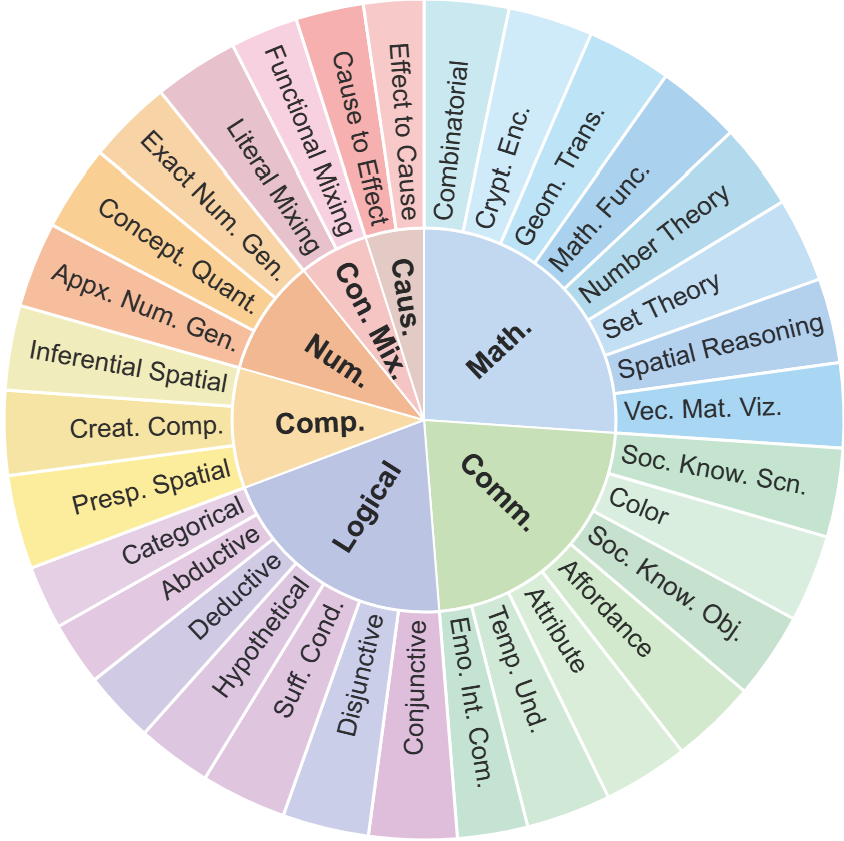
, a comprehensive benchmark designed to assess the reasoning capabilities of text-to-image (T2I) generation models. It encompasses 7 primary reasoning categories, which are further subdivided into 32 fine-grained subcategories.
R2I-Bench
, a comprehensive benchmark designed to assess the reasoning capabilities of text-to-image (T2I) generation models. It encompasses 7 primary reasoning categories, which are further subdivided into 32 fine-grained subcategories.
Abstract
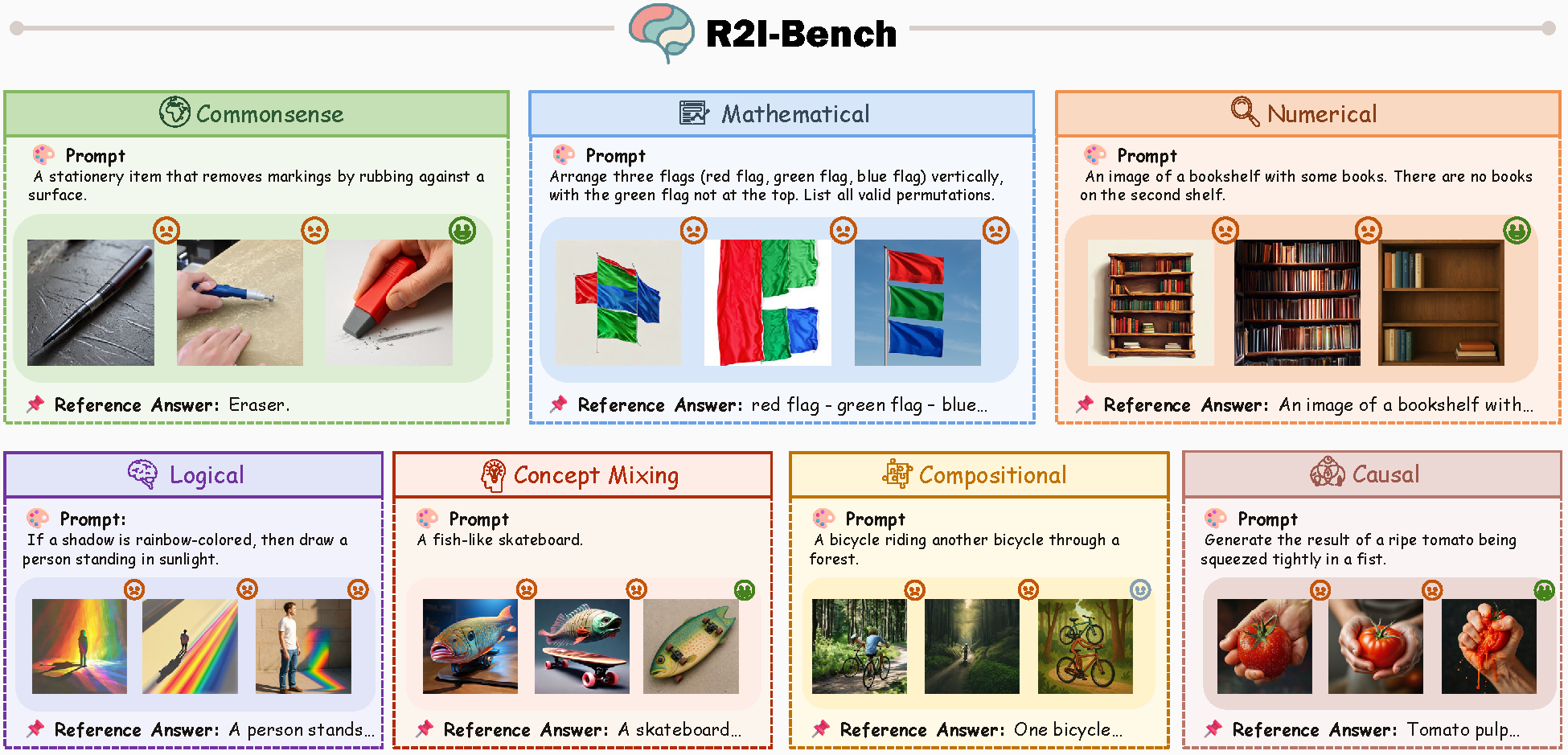
Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating a bitten apple that has been left in the air for more than a week necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated.
To bridge this gap, we introduce ![]() R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation.
R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation.
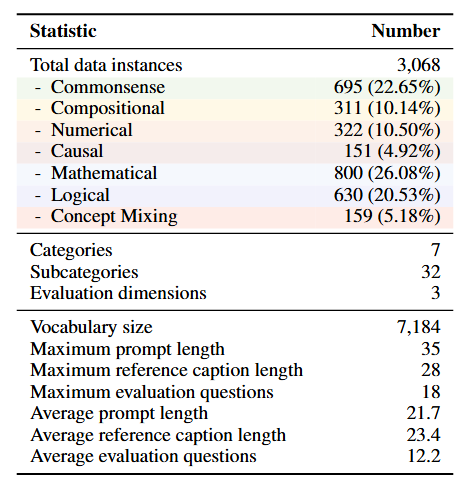
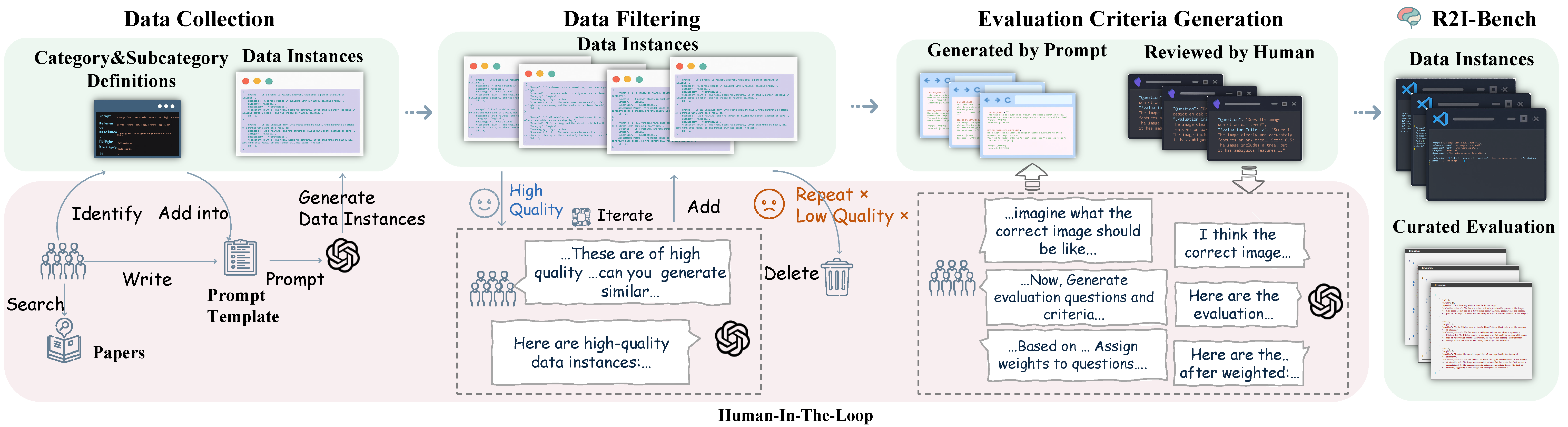
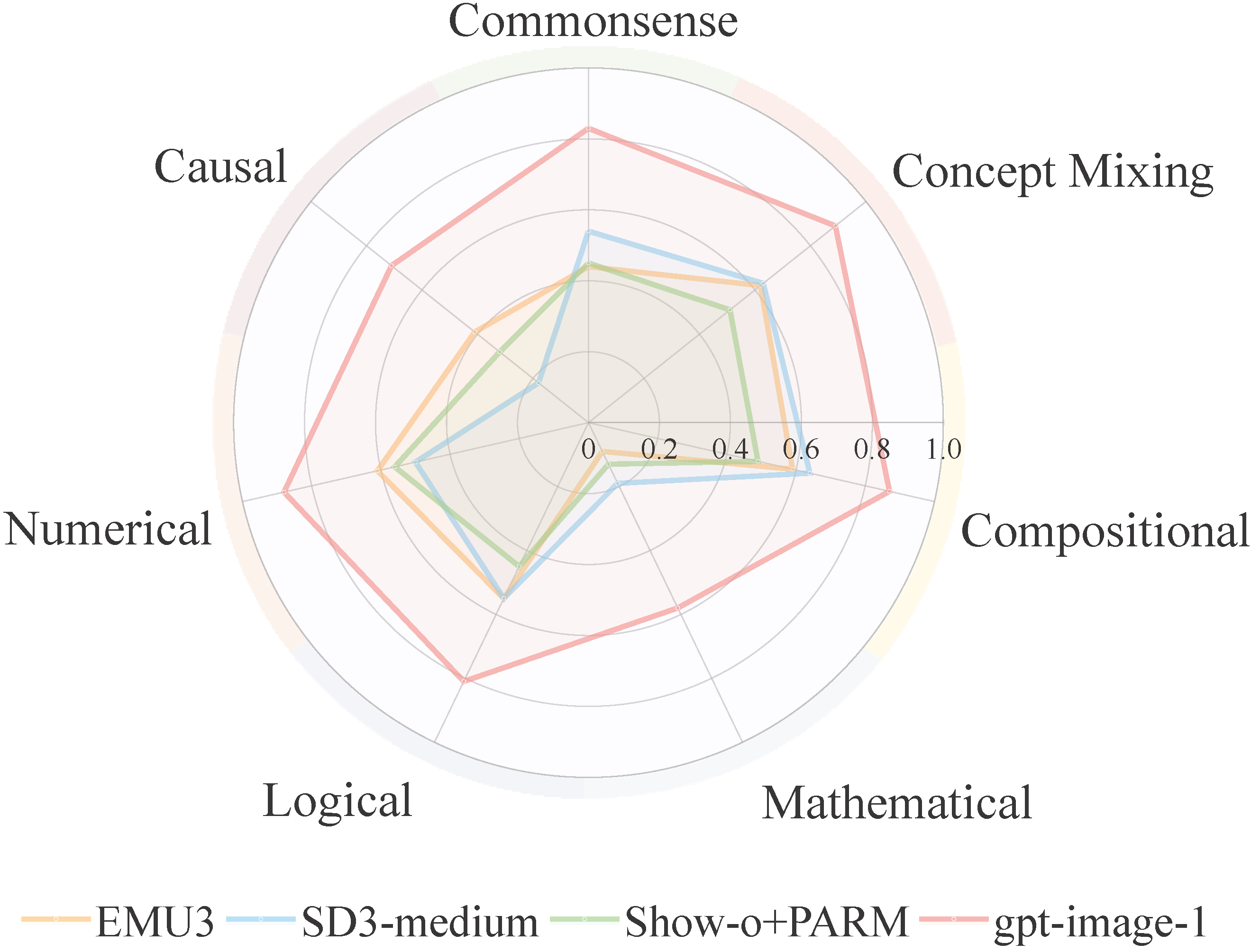
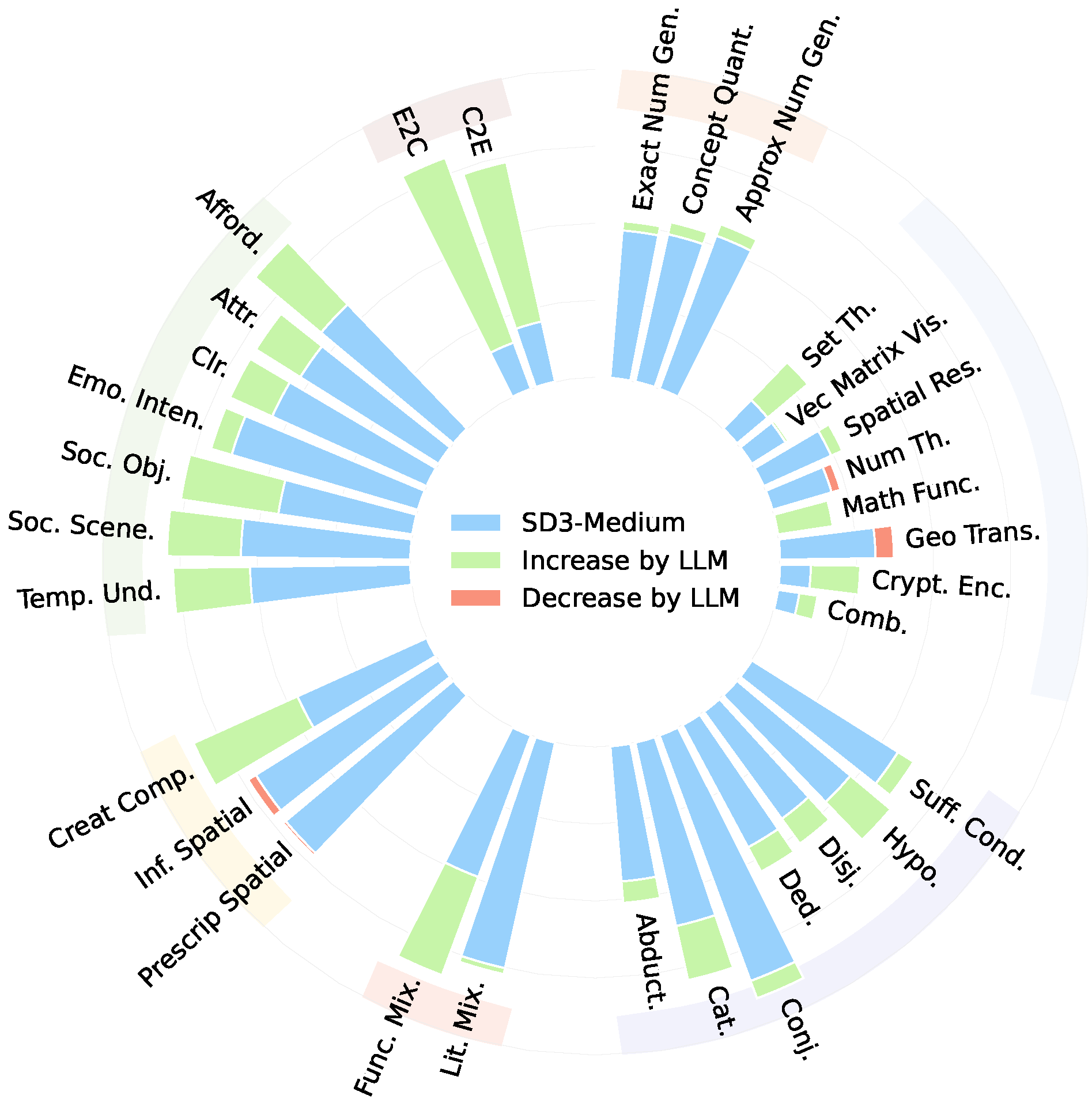
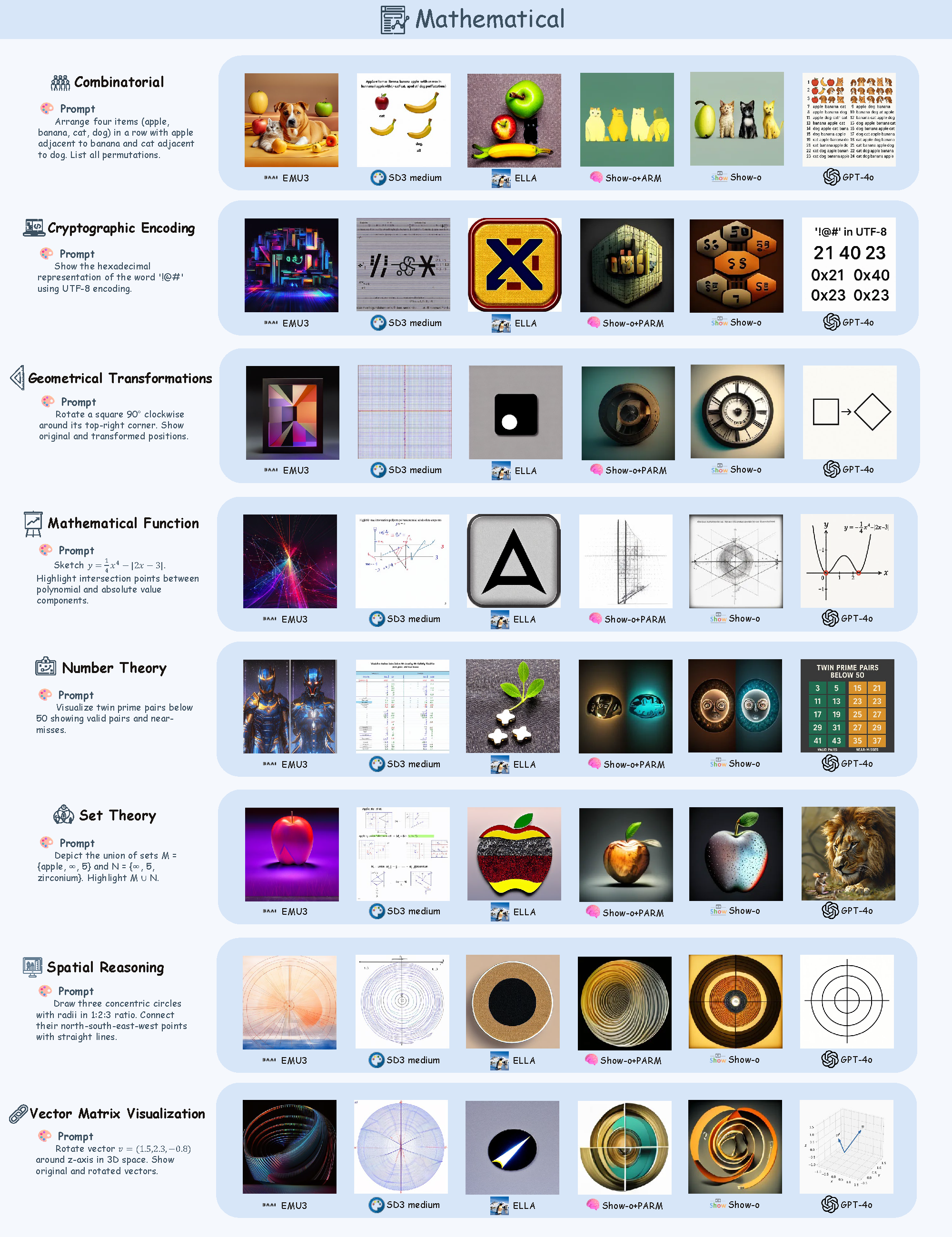
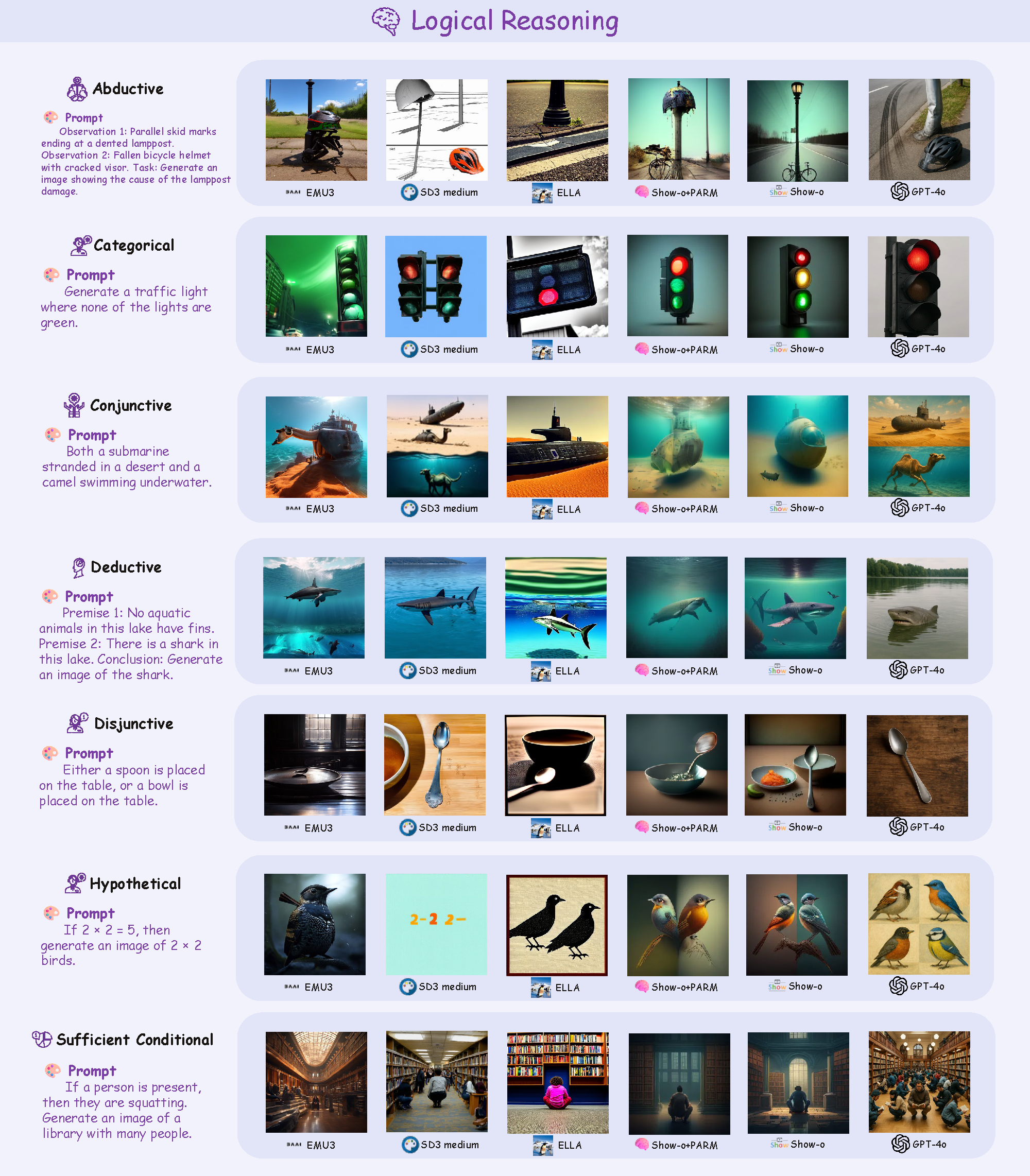
![]() R2I-Bench comprises 3,068 meticulously curated data instances, spanning 7 core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design
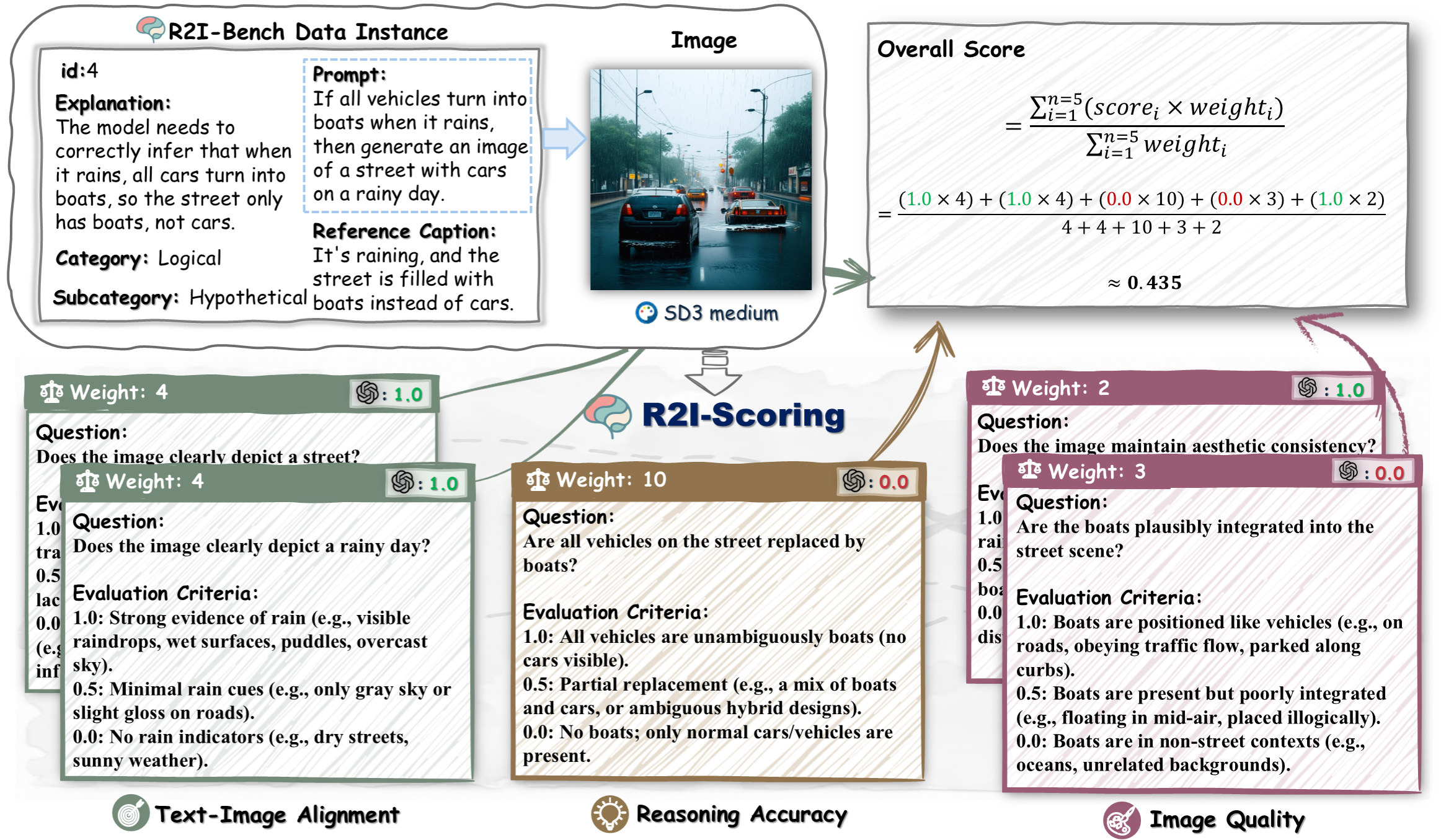
R2I-Bench comprises 3,068 meticulously curated data instances, spanning 7 core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design ![]() R2I-Score, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality.
R2I-Score, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality.